
 Today many software startups follow the ideas introduced by Eric Ries in his best-selling book “The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses”. Ries is responsible for the popularization of the concept of the MVP: “The Minimum Viable Product is that version of a new product which allows a team to collect the maximum amount of validated learning with the least effort.” The MVP should have the core features which allow it to be deployed to some real customers in order to get initial feedback, but not more.
Today many software startups follow the ideas introduced by Eric Ries in his best-selling book “The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses”. Ries is responsible for the popularization of the concept of the MVP: “The Minimum Viable Product is that version of a new product which allows a team to collect the maximum amount of validated learning with the least effort.” The MVP should have the core features which allow it to be deployed to some real customers in order to get initial feedback, but not more.
 The MVP is used in the context of the “build-measure-learn” feedback loop. From the Lean Startup site: “The first step is figuring out the problem that needs to be solved and then developing a minimum viable product (MVP) to begin the process of learning as quickly as possible. Once the MVP is established, a startup can work on tuning the engine. This will involve measurement and learning and must include actionable metrics that can demonstrate cause and effect question.”
The MVP is used in the context of the “build-measure-learn” feedback loop. From the Lean Startup site: “The first step is figuring out the problem that needs to be solved and then developing a minimum viable product (MVP) to begin the process of learning as quickly as possible. Once the MVP is established, a startup can work on tuning the engine. This will involve measurement and learning and must include actionable metrics that can demonstrate cause and effect question.”
As Ries explains in one of his blog posts: “In other words, the Minimum Viable Product is a test of a specific set of hypotheses, with a goal of proving or disproving them as quickly as possible. One of the most important of these hypotheses is always: what will the customer care about? How will they define quality?”
This application of the build-measure-learn feedback loop is proposed by Eric Ries as the most effective way to learn about what the customers really want. There is a basic assumption that the first users of our product may provide us valuable data from which we will be able to extrapolate the needs of all other users. But there is another very important book that should make us question this assumption.
Crossing the Chasm
 Geoffrey A. Moore is the author of the best-selling book “Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers“, in which he describes the five main customer segments in a technology startup’s market: innovators, early adopters, early majority, late majority and laggards.
Geoffrey A. Moore is the author of the best-selling book “Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers“, in which he describes the five main customer segments in a technology startup’s market: innovators, early adopters, early majority, late majority and laggards.
Innovators: “Pursue new technology products aggressively. They sometimes seek them out even before a formal marketing program has been launched.”
Early Adopters: “Buy into new product concepts very early in their life cycle… find it easy to imagine, understand, and appreciate the benefits of new technology.”
Early Majority: “Are driven by a strong sense of practicality… want to see well-established references before investing substantially.”
Late Majority: “Wait until something has become an established standard, and even so they want to see lots of support.”
Laggards: “Don’t want anything to do with new technology.”
These customer segments correspond to the stages in the Technology Adoption Life Cycle: the innovators are the first to buy a new product, followed by the early adopters, and so on. However, Moore claims that there is a chasm between the early adopters and the early majority, which is illustrated in the picture below.
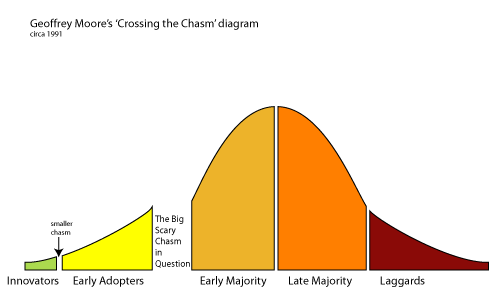
According to Moore, there is a huge difference between the early adopters and the early majority:
Early adopters are buying some kind of change agent. “By being the firsts to implement this change in their industry, the early adopters expect to get a jump on the competition… They expect a radical discontinuity between the old ways and the new… They also are prepared to bear with the inevitably bugs and glitches that accompany any innovation just coming to market.”
In contrast, the early majority want a productivity improvement. “They want evolution, not revolution. They want technology to enhance, not overthrow, the established ways of doing business. And above all, they do not want to debug someone’s else product… They want it to work properly and to integrate appropriately with their existing technology base.”
Over-fitting to Early Adopters
In my opinion it is clear that if we adopt the build-measure-learn feedback loop while in the early adopters stage, we are incurring the risk of learning about user needs and preferences of a small segment which is very different from the main market, represented by the early and late majority segments.
Another way to say that is that we are using the build-measure-learn feedback loop in order to build a model to predict the behavior of our users. In this case we are incurring the risk of over-fitting this model to the particular user segment which is currently providing its feedback.
Definition of over-fitting: “A modelling error which occurs when a function is too closely fit to a limited set of data points. Over-fitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study. In reality, the data being studied often has some degree of error or random noise within it. Thus attempting to make the model conform too closely to slightly inaccurate data can infect the model with substantial errors and reduce its predictive power.”
Note that the feedback provided by the early adopters has the two main problems that appear in the definition above:
- It is a “limited set of data points”: the early adopters are a small and very specific segment, and not a random sample of our potential users.
- It “has some degree of error or random noise within it” since the behavior of the early adopters is different from the majority of the users.
In Summary
We should be very careful when using the build-measure-learn feedback loop while in the early adopters stage. Possible ways to reduce the risks of over-fitting to this very specific user segment require understanding the differences between the early adopters and the majority of our potential users.

I suggest reading the book “running lean” which helped me understand how i could apply this lifecycle depending on the stage of my startup.
Nice post Hayim!
I would probably say that initially you use the lean feedback loop to fit your target the available market which is the early adopters. Once you approach the chasm you can start using the lean feedback loop to target the next available market. and that learning/experimentation will be both about product as well as whole solution, full kit, case studies, etc.
Bottom line you have uncertainty about product market fit both in the early adopters stage as well as the early majority (and probably later on as well) and the lean feedback loop can help navigate through that uncertainty. Obviously some “Effective Software Design/Intent” should be used to minimize the impact of learning and pivoting. And of course a lot of care should be given to avoiding TOO much design for flexibility if it actually slows down the lean feedback loop too much… Balancing all these forces is what makes it so much fun 🙂
Thanks for your comment, Yuval. I think the key point as you said is to be aware that in the early stages the startup company is dealing with lots of uncertainty. Unfortunately it is very easy to fall in the trap of excessive optimism and believe that the initial exponential growth will continue.